
Pendant une heure, Léo a démystifié l’intelligence artificielle (IA), en explorant ses différents types – génératives et non-génératives – et en détaillant leur fonctionnement. Il a également mis en lumière leurs applications pédagogiques, ouvrant des perspectives passionnantes pour l’enseignement et l’apprentissage.
Le live a abordé des thématiques essentielles comme le coût, l’éthique et l’impact environnemental des technologies d’IA, avant de se conclure sur une session de questions-réponses. Une plongée fascinante au cœur d’une révolution technologique qui touche tous les domaines, y compris l’éducation !
Plongée au cœur de l’IA avec Léo Briand
Léo Briand est le fondateur de Vittascience, un opérateur majeur dans le développement de la culture numérique, particulièrement en milieu scolaire.
Il présente la mission de Vittascience qui est de former les publics à l’intelligence artificielle (IA), notamment en milieu scolaire et au-delà. Ainsi, la plateforme compte 300 000 élèves et enseignants qui l’utilisent. Enfin, le site propose une gamme de produits, incluant des produits matériels comme des kits avec des Raspberry Pi4.
Léo souligne qu’il est essentiel de s’intéresser à l’intelligence artificielle, quelles que soient ses responsabilités et son travail, pour ne pas être dépassé par ceux qui la maîtrisent :
L’IA est un sujet incontournable car elle va impacter quasiment tous les métiers, à l’exception peut-être des plus manuels.
Les outils d’IA développés par Vittascience permettent d’explorer l’IA générative et non-générative et de comprendre son fonctionnement en « touchant du doigt ce qu’il y a sous le capot ».
Comprendre le fonctionnement de l’intelligence artificielle : types d’IA et leur fondamentaux
Dans le domaine de l’intelligence artificielle (IA), Léo explique qu’il faut distinguer les IA génératives des IA non-génératives. Ces deux catégories d’IA diffèrent considérablement dans leur fonctionnement et leurs applications.
Qu’est-ce que l’intelligence artificielle générative ?
Les IA génératives sont conçues pour créer du contenu, qu’il s’agisse de texte, d’images ou d’autres types de données. Les plus connues incluent ChatGPT, Mistral et Claude pour la génération de texte et DALL-E ou MidJourney pour la génération d’images.
Il explique que le fonctionnement de ces IA repose sur un processus où, à partir d’un prompt (une description textuelle), le modèle va générer le contenu souhaité. Les IA génératives de texte, par exemple, prédisent le prochain token (un petit bout de mot) le plus probable, générant ainsi du texte mot après mot. Dans le cas de la génération d’images, l’IA part d’un ensemble de pixels aléatoires pour arriver à une image cohérente, en passant par plusieurs étapes.

Les IA génératives sont malléables et permettent une grande créativité, mais les modèles sont complexes à entraîner.
Bien qu’elles soient populaires, les IA génératives sont en réalité moins utilisées que les IA non-génératives.
Qu’est-ce que l’intelligence artificielle non-générative ?
Les IA non-génératives sont principalement utilisées pour la détection, la reconnaissance, et la classification. Elles ne créent pas de contenu nouveau.
Des exemples concrets d’IA non-génératives incluent la reconnaissance d’image (reconnaissance faciale, d’objets, d’animaux), la reconnaissance de son (détection de musique), et la reconnaissance de posture. Contrairement aux IA génératives, les IA non-génératives sont entraînées à partir d’un ensemble de données pour identifier des patterns et prendre des décisions basées sur ces patterns.
Par exemple, pour entraîner une IA de reconnaissance d’images, on fournit un ensemble d’images étiquetées par catégories (ex: « main ouverte » vs « main fermée ») afin que l’IA puisse apprendre à les distinguer.
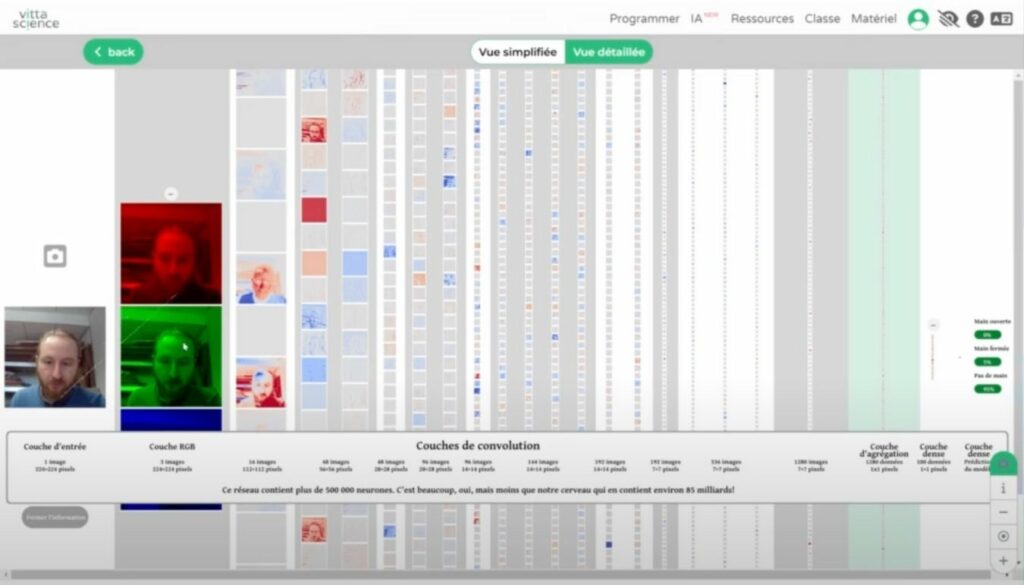
Ces modèles peuvent être entraînés directement dans un navigateur, sur le site de Vittascience, ce qui permet de les personnaliser pour des cas d’usage spécifiques tout en respectant les règles de protection des données personnelles (RGPD).
Bon à savoir : Pour réduire sa dépense énergétique, Vittascience utilise le modèle MobileNet V2 pour la reconnaissance d’image. Son architecture légère permet un déploiement efficace sur des appareils mobiles et embarqués disposant de ressources de calcul limitées.
Qu’est-ce-qu’un LLM ?
Un LLM (Large Language Model), ou grand modèle de langage, est un type d’intelligence artificielle (IA) utilisé pour le traitement du langage.
Léo explique qu’un LLM est un modèle de réseau neuronal très avancé. Il prend en entrée un texte, comme une question ou une phrase, et prédit le mot ou le token suivant le plus probable. Cette prédiction se fait en analysant l’historique de la phrase et en calculant les probabilités d’apparition de chaque token possible. Le modèle contient des milliards de paramètres qui permettent de faire ces prédictions.
Les LLM sont utilisés dans les IA génératives pour créer du texte, par exemple pour répondre à des questions ou écrire des articles. Le processus de génération de texte est itératif, où pour chaque nouveau token généré, le réseau neuronal est relancé.
Les enjeux autour de l’IA
Léo nous explique que l’IA présente de nombreux défis au-delà des questions techniques.
Il souligne qu’il faut être prudent face aux biais au manque de transparence des entreprises, et à l’impact sur l’emploi qui sont des préoccupations majeures sur le plan éthique.
Sans être alarmiste non plus, il donne l’exemple du métier de développeur web :
L’IA ne va remplacer pas les développeurs, mais plutôt qu’elle va transformer leurs rôles et les compétences nécessaires. […] Le métier de « prompt engineer » ne sera probablement pas un métier à part entière. Mais, il y aura une demande croissante pour des professionnels capables d’entraîner et d’adapter des IA à des contextes spécifiques.
Enfin, Léo insiste sur l’importance d’éduquer les citoyens à l’esprit critique et de développer des outils qui permettent de mieux comprendre le fonctionnement des IA. Enfin, il rappelle l’intérêt des modèles open source et des services d’IA « as a service » qui contribuent à démocratiser l’accès à cette technologie.
Pourquoi l’utilisation de l’intelligence artificielle doit être régulée ?
La conversation revient sur le sujet des enjeux environnementaux et de dépenses énergétiques significatifs des intelligences artificielles, en particulier pour les modèles les plus complexes.
Léo précise que les modèles d’IA, notamment les IA génératives comme celles utilisées pour le texte ou les images, nécessitent une grande quantité d’énergie pour fonctionner. Cette consommation est due aux calculs complexes réalisés par les réseaux neuronaux avec des milliards de paramètres. L’entraînement de ces modèles requiert des ressources considérables en puissance de calcul et en énergie, ce qui a un impact environnemental et un coût financier élevé.
NDLR : Selon une étude de Schneider Electric, la charge des workloads d’IA aura représenté environ 4,3 GW en 2023, soit 8% de la consommation globale des datacenters (57 GW).
Il ajoute que l’utilisation de la technique de Retrieval Augmented Generation (RAG), qui permet à l’IA d’accéder à des documents pour mieux contextualiser ses réponses, augmente significativement la consommation énergétique, car l’IA doit lire les documents avant de répondre.
Toutefois, il précise qu’il est possible de réduire « légèrement » les coûts d’un modèle existant en l’adaptant. Il s’agit du fine tuning une pratique qui consiste à spécialiser un modèle pré-entraîné de Machine Learning sur une tâche spécifique. Par exemple, une entreprise peut utiliser le fine tuning pour créer un LLM capable de répondre aux questions spécifiques sur ses produits.
Enfin, Léo recommande d’utiliser un navigateur de recherche (Google ou Ecosia) pour des requêtes simples ou factuelles, comme trouver une date ou une information de base, un moteur de recherche traditionnel est beaucoup plus efficace d’un point de vue énergétique qu’une IA générative.
Pour les autres questions que soulèvent l’IA, Léo ajoute qu’il ne faut pas négliger les deux types de problèmes fréquents que sont les hallucinations et les biais :
Les hallucinations se produisent lorsque l’IA commence à raconter n’importe quoi, souvent parce qu’un premier token (unité de base du texte pour l’IA) est erroné. […] Si l’IA commence avec une information factuellement fausse, elle continue à construire la phrase de manière cohérente avec cette fausse information.
Les biais quant à eux surviennent lorsque l’IA est entraînée sur des données non représentatives ou si les critères de décision ne sont pas neutres.
Léo a donné un exemple concret avec un modèle de reconnaissance d’images qui détectait la présence d’une main en se basant sur l’arrière-plan plutôt que sur la main elle-même. L’IA avait été entraînée avec des images où la main était toujours dans le même contexte. Un autre exemple de biais qu’il mentionne est un problème de biais racial qui a été observé dans un système de reconnaissance faciale, où l’IA reconnaissait principalement des personnes de couleur.
Il explique qu’il est quasiment impossible d’éliminer complètement les biais et que tous les modèles se tromperont à un moment donné.
Pour terminer, Léo souligne qu’il est important d’adapter les outils aux cas d’usage : pour les requêtes informatives, un moteur de recherche classique est plus approprié, car beaucoup moins énergivore. Pour des tâches plus complexes qui demandent une compréhension fine du langage, une intelligence artificielle sera plus pertinente. Il conclut que l’autorégulation par les coûts pourrait jouer un rôle important dans l’utilisation raisonnable des IA.



